
Snowflake Summit – in a Nutshell
Snowflake Summit 2023 is in the books. It was all data, all AI and LLMs. LLMs are the big hype. Snowflake announced a big strategic partnership with NVIDIA. NVIDIA plans to bring their ‘NeMo platform for training and running generative AI models into Snowflake’ according to Reuters. Other announcements include Snowpark Container Services, Streamlit, Native Apps, Native ML and AI capabilities, Iceberg Tables, FinOps features and some core enhancements of Snowflake’s platform. Read along for a good overview of the latest and greatest in the Snowflake Data Cloud. The
Here is an overview of the announcements:
- Snowpark Container Services (New Feature!)
- Streamlit & Native Apps
- Generative AI & ML Capabilities (New Features!)
- Iceberg Tables
- Streaming Enhancements
- Dynamic Tables (New Feature!)
- FinOps Capabilities
- Core Enhancements
Snowpark Container Services
Snowflake now supports Docker containers. That means, you can run any job, function or services from inside the platform eliminating the need to leverage other platforms like AWS. This enables users to leverage 3rd party LLMs, HEX notebooks, c++ apps or full databases like Pinecone to enrich their data use cases.
Streamlit & Native Apps
Since its acquisition, Streamlit has grown to become a very popular solution to build intuitive user interfaces, now even competing with the Javascript-based framework react. Streamlit’s open-source python-based library is compatible with major libraries such as sckit-learn, pytorch or pandas. It’s also offering an integration with Gitlab and Github for version control.
Generally, there is an immense focus on native apps at Snowflake, trying to bring data as well as code into the platform. Snowflake launched the Native App Framework on AWS and implemented a smart monetization system through their marketplace for data and native apps. Developers can define their pricing model individually. Event-based pricing is now available alongside the traditional consumption based pricing. Event-based pricing includes pricing based on inserted or updated rows as well as based on rows scanned.
Generative AI and ML
With its latest acquisitions Applica and Neeva, Snowflake is investing hard into generative AI and ML capabilities. In a live demo during the main keynote, they presented their newest Document AI feature leveraging Applica’s technology. This allows users to query unstructured data, such as handwritten machine failure reports from the factory. This is a major innovation and makes the platform even more relevant to the manufacturing industry, amongst many other use cases.
Unstructured data is persisted and vectorized inside of Snowflake. It can also now be queried in natural language using the search engine of Neeva.
Iceberg Tables
Last year, Snowflake announced the support of Iceberg Tables. Now they have been fully integrated into Snowflake’s security, governance and query optimizer resulting in equal performance results for both Iceberg and native tables. More about Apache Iceberg can be found here.
Streaming
Streaming with Kafka has become an increasingly popular way of integrating data into Snowflake. While previously data had to be staged in an object storage before it was loaded into the table, now it’s possible to ingest data directly into a table. This makes data ingestion using Kafka a lot simpler and user friendly.
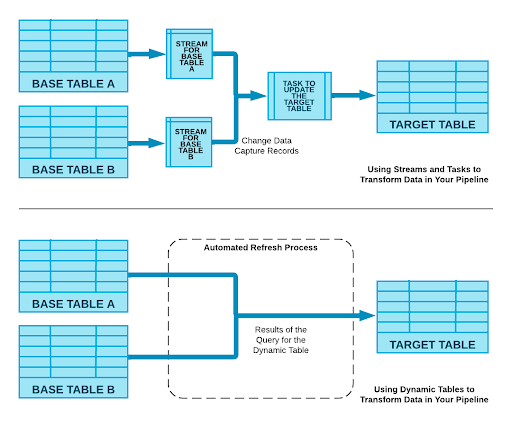
Dynamic Tables
A completely new feature – dynamic tables are also called ‘declarative pipelines’. Dynamic tables massively simplify the experience of creating data pipelines in Snowflake. While previously, data engineers had to leverage Streams and Tasks along with manually managing database objects, they now can do all of this with a single feature. Dynamic tables also automatically refresh as the underlying data changes. For illustration, see the below diagram as well as SQL code examples taken from Snowflake’s public announcement.
SQL Statement for Streams and Tasks
— Create a landing table to store
— raw JSON data.
create or replace table raw
(var variant);
— Create a stream to capture inserts
— to the landing table.
create or replace stream rawstream1
on table raw;
— Create a table that stores the names
— of office visitors from the raw data.
create or replace table names
(id int,
first_name string,
last_name string);
— Create a task that inserts new name
— records from the rawstream1 stream
— into the names table.
— Execute the task every minute when
— the stream contains records.
create or replace task raw_to_names
warehouse = mywh
schedule = ‚1 minute‘
when
system$stream_has_data(‚rawstream1‘)
as
merge into names n
using (
select var:id id, var:fname fname,
var:lname lname from rawstream1
) r1 on n.id = to_number(r1.id)
when matched and metadata$action = ‚DELETE‘ then
delete
when matched and metadata$action = ‚INSERT‘ then
update set n.first_name = r1.fname, n.last_name = r1.lname
when not matched and metadata$action = ‚INSERT‘ then
insert (id, first_name, last_name)
values (r1.id, r1.fname, r1.lname);
SQL Statements for Dynamic Tables
– Create a landing table to store
— raw JSON data.
create or replace table raw
(var variant);
— Create a dynamic table containing the
— names of office visitors from
— the raw data.
— Try to keep the data up to date within
— 1 minute of real time.
create or replace dynamic table names
lag = ‚1 minute‘
warehouse = mywh
as
select var:id::int id, var:fname::string first_name,
var:lname::string last_name from raw;
FinOps Capabilities
Snowflake has often been criticized for its high cost and low transparency. Therefore, there has been a strong focus on bringing out new enhancements and features to drive cost improvement.
The Snowflake Performance Index has been announced as an ML-powered optimization algorithm for stable workloads. Results show a 15% cost improvement. Snowflake is going to leverage this index to further improve and drive transparency on cost.
Also budgets have been enabled as a new feature. Workloads can be assigned to budgets and users can be notified once budgets are hit or exceeded.
Core Enhancements
Data quality is an important topic for many organizations as their data storage grows. Users can now define metrics to gather statistics on column value distributions, null values and more. The results are stored in time-series based tables allowing to build thresholds and detect anomalies from regular patterns.
SnowSQL improvements have been made, including the exclusion of particular columns from a select * statement (this has been a pain prior to this). You can now select all columns and exclude the ones you don’t want to see, using the exclude statement. Also you can group by ‘all’ now.
Snowflake warehouses are the compute engines of the platform. They can now be sized based on demand patterns allowing companies to further optimize resource utilization.
Lastly, ML functions can now be called directly from SQL code, democratizing the use of the likes of forecasting or anomaly detection models even further. AutoSQL using LLMs help to auto-generate SQL code and increase productivity of data engineers.
Conclusion
It’s all AI and ML. But the reality is, information is still siloed, data is still trapped in systems and scattered across organisations.



